
Debido a los dos objetivos distintos que un análisis de regresión puede tener es difícil establecer una estrategia general para encontrar el mejor modelo de regresión, es más, el mejor modelo significa cosas distintas con cada objetivo.
En un análisis predictivo el mejor modelo es el que produce predicciones más fiables para una nueva observación, mientras que en un análisis estimativo el mejor modelo es el que produce estimaciones más precisas para el coeficiente de la variable de interés.
En ambos casos se prefiere el modelo más sencillo posible (a este modo de seleccionar modelos se le denomina parsimonia), de modo que en un análisis estimativo, se puede excluir del modelo una variable que tenga un coeficiente significativamente distinto de cero y que su contribución a la predicción de la variable dependiente sea importante, porque no sea variable de confusión para la variable de interés (el coeficiente de dicha variable no cambia), en un análisis predictivo esa variable no se excluiría.
Sin
embargo, hay una serie de pasos que deben realizarse siempre:
i) Especificación del modelo máximo.
ii) Especificación de un criterio de comparación de modelos y definición de una
estrategia para realizarla.
iii) Evaluación de la fiabilidad del modelo.
i) Especificación del modelo máximo
Se trata de establecer todas las variables que van a ser consideradas. Recuérdese que el modelo saturado (el máximo que se puede considerar) tiene n - 1 variables pero que, en general, el modelo saturado no tiene interés y el modelo máximo deberá tener menos variables independientes que el modelo saturado (un criterio habitual es incluir como máximo una variable cada 10 eventos).
El criterio para decidir qué variables forman el modelo máximo lo establece el investigador en función de sus objetivos y del conocimiento teórico que tenga sobre el problema, evidentemente cuanto menor sea el conocimiento previo mayor tenderá a ser el modelo máximo.
Un modelo máximo grande minimiza la probabilidad de error tipo II o infraajuste, que en un análisis de regresión consiste en no considerar una variable que realmente tiene un coeficiente de regresión distinto de cero.
Un modelo máximo pequeño minimiza la probabilidad de error tipo I o sobreajuste (incluir en el modelo una variable independiente cuyo coeficiente de regresión realmente sea cero).
Debe tenerse en cuenta también que un sobreajuste, en general, no introduce sesgos en la estimación de los coeficientes (los coeficientes de las otras variables no cambian), mientras que un infraajuste puede producirlos, pero que un modelo máximo grande aumenta la probabilidad de problemas de colinealidad.
En el modelo máximo deben considerarse también los términos de interacción que se van a introducir (en un modelo estimativo sólo interesan interacciones entre la variable de interés y las otras)
ii) Comparación de modelos
Debe establecerse cómo y con qué se comparan los modelos. Si bien hay varios estadísticos sugeridos para comparar modelos, el más frecuentemente usado es el logaritmo del cociente de verosimilitudes, recordando que cuando los dos modelos sólo difieren en una variable, el contraste con el logaritmo del cociente de verosimilitudes es equivalente al contraste de Wald, pero a veces interesa contrastar varias variables conjuntamente mejor que una a una (por ejemplo todos los términos no lineales) o, incluso, es necesario hacerlo (por ejemplo para variables indicadoras).
Hay que hacer notar que en un análisis estimativo el criterio para incluir o excluir variables distintas a las de interés, es sobre todo los cambios en los coeficientes y no los cambios en la significación del modelo.
Los distintos modelos a comparar se pueden construir de dos formas: por eliminación o hacia atrás ("backward") y por inclusión o hacia adelante ("forward").
Con la primera estrategia, se ajusta el modelo máximo y se calcula el logaritmo del cociente de verosimilitudes para cada variable como si fuera la última introducida (que es equivalente al contraste de Wald para esa variable), se elige el menor de ellos y se contrasta con el nivel de significación elegido. Si es mayor o igual que el valor crítico se adopta este modelo como resultado del análisis y si es menor se elimina esa variable y se vuelve a repetir todo el proceso hasta que no se pueda eliminar ninguna variable.
Con la estrategia hacia adelante, se empieza con un modelo de una variable, aquella que presente el mejor logaritmo del cociente de verosimilitudes. Se calcula el logaritmo del cociente de verosimilitudes para la inclusión de todas las demás, se elige el menor de ellos y se contrasta con el nivel de significación elegido. Si es menor que el valor crítico, se para el proceso y se elige el modelo simple como mejor modelo, y si es mayor o igual que dicho valor crítico, esa variable se incluye en el modelo y se vuelve a calcular el logaritmo del cociente de verosimilitudes para la inclusión de cada una de todas las restantes, y así sucesivamente hasta que no se pueda incluir ninguna más.
Una modificación de esta última estrategia es la denominada "stepwise" que consiste en que, cada vez que con el criterio anterior se incluye una variable, se calculan los logaritmos del cociente de verosimilitudes de todas las incluidas hasta ese momento como si fueran las últimas y la variable con menor logaritmo del cociente de verosimilitudes no significativo, si la hubiera, se elimina. Se vuelven a calcular los logaritmos del cociente de verosimilitudes y se continua añadiendo y eliminando variables hasta que el modelo sea estable.
Las variaciones a estas estrategias consisten en que, con cualquiera de ellas, se puede contrastar varias variables en lugar de una sola y que, en aplicación del principio jerárquico, cuando se contrasta un término de interacción, el modelo debe incluir todos los términos de orden inferior y, si como resultado del contraste, dicho término permanece en el modelo, también ellos deben permanecer en el mismo, aunque no se pueda rechazar que los coeficientes correspondientes no son distintos de cero.
En cualquier caso, puede ser peligroso aplicar cualquiera de estas estrategias automáticamente (con un paquete estadístico, por ejemplo) por lo que se ha comentado más arriba sobre los distintos criterios dependiendo del objetivo del estudio, los términos de interacción y las variables indicadoras.
Ejemplo 10
Estimar el efecto de los receptores de progesterona en la mortalidad de pacientes operadas de cáncer de mama. Datos: serie de 152 mujeres operadas entre Oct 89 y Ene 92; 51 de ellas muertas por el tumor. Tenemos: las fechas de nacimiento y cirugía, grado histológico (1, 2 y 3), tamaño del tumor (en cm), número de ganglios afectados, y receptores de estrógenos y progesterona.
El modelo máximo estaría formado por las variables: receptores de progesterona (por ser la variable de interés), estrógenos, edad, tamaño, grado y número de ganglios (por si son variables de confusión); podemos considerar también el término de interacción entre los receptores de progesterona y el tamaño; como grado histológico está codificado en 3 niveles podría ser conveniente analizarlo a través de 2 variables indicadoras
Para decidir si grado histológico se introduce en el modelo como está o con variables indicadoras, se compara el modelo que la contenga como está con otro que tenga las indicadoras.
a) modelo con grado histológico en una sola variable


b) modelo con grado histológico con dos variables indicadoras



De acuerdo a la prueba del logaritmo del cociente de verosimilitudes, el modelo ajusta ligeramente peor con las variables indicadoras, se observa también que la variable no cumple la asunción de “multiplicatividad” (el coeficiente de la indicadora GRADO(2) (1,882) no es el doble del de GRADO(1) (1,398) o, equivalentemente, el OR correspondiente a GRADO(2) (6,569) no es el cuadrado del correspondiente a GRADO(1) (4,045), si bien la estimación de ambos ORs es muy imprecisa (ICs tan amplios que incluyen la desviación de la multiplicatividad) debido a que sólo hay 10 individuos en la categoría que se está usando como referencia. En consecuencia, usaremos la variable original. Hay que resaltar que solo hay 51 eventos, que son insuficientes para estudiar un modelo máximo de 7 variables
Se ajusta el modelo máximo

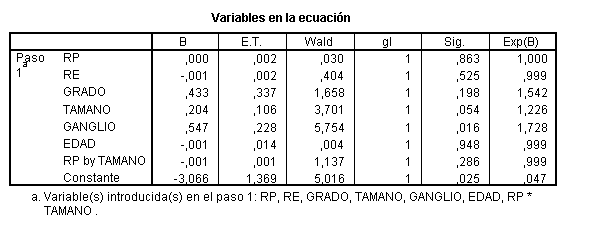
La variable menos significativa es EDAD, la eliminamos para evaluar si es variable de confusión.
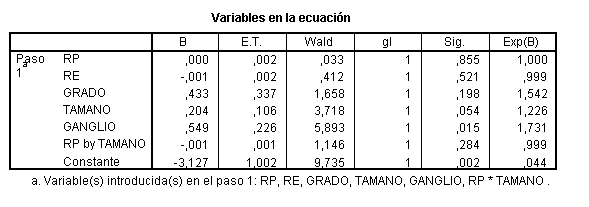
Ni el OR de RP, ni el de RP por TAMAÑO han cambiado, por lo tanto EDAD no es una variable de confusión y puede ser eliminada; la menos significativa ahora es RP, que no puede ser eliminada en este punto (por el principio jerárquico y por ser nuestra variable de interés), la siguiente es RE, que la eliminamos
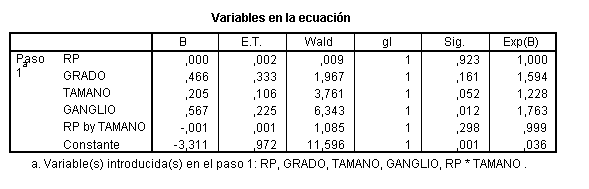
Tampoco ahora han cambiado ni el OR de RP, ni el de RP por TAMAÑO, por lo tanto RE no es una variable de confusión y puede ser eliminada; la menos significativa ahora es RP, que por las mismas razones que antes no puede ser eliminada y la siguiente RP por TAMAÑO, que es la que eliminamos (no existe interacción entre RP y TAMAÑO).
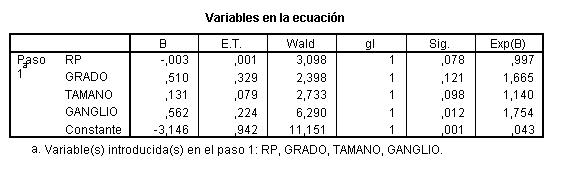
La menos significativa es GRADO
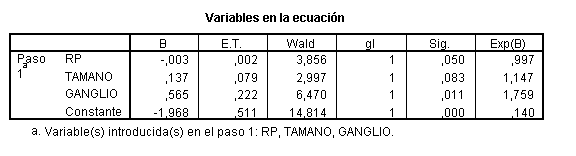
El OR de RP no ha cambiado, por tanto se puede eliminar GRADO; la menos significativa ahora es TAMAÑO
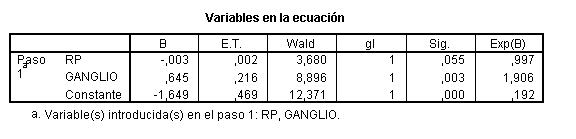
que tampoco es variable de confusión y por lo tanto puede ser eliminada. La variable GANGLIO es significativa, pero en aplicación del principio de parsimonia podría eliminarse del modelo si no fuera variable de confusión

Efectivamente no es variable de confusión y este último será el modelo final.
iii) Evaluación de la fiabilidad del modelo
Una vez encontrado el mejor modelo hay que evaluar su fiabilidad, es decir, evaluar si se comporta igual en otras muestras extraídas de la misma población (reproducibilidad) y/o de otras similares (transportabilidad).
Lo veremos con detalle más adelante
Otras lecturas
Silva Ayçaguer L.C., Barroso Utra I.M. Selección algorítmica de modelos en las aplicaciones biomédicas de la regresión múltiple. Medicina Clínica. 2001;116:741-745.

|

|

|

|