
Interacción y confusión en la regresión logística
Los modelos de regresión, como en el caso lineal, pueden usarse con dos objetivos: 1) predictivo en el que el interés del investigador es predecir lo mejor posible la variable dependiente, usando un conjunto de variables independientes y 2) estimativo en el que el interés se centra en estimar la relación de una o más variables independientes con la variable dependiente. El segundo objetivo es el más frecuente en estudios etiológicos en los que se trata de encontrar factores determinantes de una enfermedad o un proceso.
La interacción y la confusión son dos conceptos importantes cuando se usan los modelos de regresión con el segundo objetivo, que tienen que ver con la interferencia que una o varias variables pueden realizar en la asociación entre otras.
Existe confusión cuando la asociación entre dos variables difiere significativamente según que se considere, o no, otra variable, a esta última variable se le denomina variable de confusión para la asociación. Existe interacción cuando la asociación entre dos variables varía según los diferentes niveles de otra u otras variables.
Veamos también aquí estos conceptos sobre los modelos. El modelo más sencillo para estudiar la asociación entre una variable binomial y otra variable X1 es
ln(p/q) = a0 + a1X1
donde
a1
cuantifica la asociación: 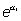 es el odds ratio por unidad de cambio en X1.
Se dice que X2 es una variable de confusión para esta
asociación, si el modelo
es el odds ratio por unidad de cambio en X1.
Se dice que X2 es una variable de confusión para esta
asociación, si el modelo
ln(p/q) = a0 + a1X1 + a2X2
produce una estimación para a1 diferente del modelo anterior. Evidentemente esta definición se puede ampliar a un conjunto de variables, se dice que las variables X2, ..., Xk son variables de confusión si la estimación de a1 obtenida por el modelo
ln(p/q) = a0 + a1 X1 + a2 X2 + ... + ak Xk
es diferente de la obtenida en el modelo simple. En ambos casos se dice que la estimación de a1 obtenida en los modelos múltiples está controlada o ajustada por X2 o por X2 ,..., Xk
Contrastar la existencia de confusión requiere, por lo tanto, comparar los coeficientes de regresión obtenidos en dos modelos diferentes y si hay diferencia, existe la confusión, en cuyo caso la mejor estimación es la ajustada. Para dicha comparación no se precisa realizar un contraste de hipótesis estadístico ya que aunque la diferencia encontrada sea debida al azar, representa una distorsión que la estimación ajustada corrige. Será el investigador quién establezca el criterio para decidir cuando hay diferencia. Lo habitual es considerar que existe confusión cuando la exponencial del coeficiente (el OR) cambia en más del 10%.
El modelo más sencillo que hace explícita la interacción entre dos variables X1 y X2 es
ln(p/q) = a0 + a1 X1 + a2 X2 + a3 X1 X2
En este modelo, el logaritmo del odds para unos valores determinados x1, x2 de X1, X2 es
ln(p/q) = a0 + a1 x1 + a2 x2 + a3 x1 x2
y para los valores x1 + 1 y x2
ln(p/q) = a0
+ a1(x1
+ 1) + a2
x2 + a3
(x1 + 1) x2
= a0
+ a1
x1 + a1
+ a2
x2 + a3
x1 x2 + a3
x2
restando ambas se encuentra el cambio en ln(p/q) por una unidad de cambio en X1 manteniendo fijo X2
a1 + a3 x2
o dicho de otra manera, el odds ratio por una unidad de cambio en X1 manteniendo fijo X2 es
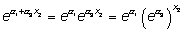
que es diferente para cada valor x2 de X2. Del mismo modo, el cambio en ln(p/q) por una unidad de cambio en X2 manteniendo fijo X1 es
a2 + a3 x1, o en términos del OR, el odds ratio por una unidad de cambio en X2 manteniendo fijo X1 es
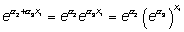
Por lo tanto, contrastar la existencia de interacción entre X1 y X2 es contrastar si el coeficiente a3 es cero (no hay interacción), o distinto de cero (existe interacción). Nótese que para poder interpretar así este contraste es necesario que en el modelo figuren las variables X1, X2 y X1X2.
En caso de que exista interacción los coeficientes los exponenciales de a1y a2por sí solos no significan nada y la asociación de las variables X1 y X2 con la binomial estará cuantificada por las expresiones anteriores.
Es obvio que primero debe contrastarse la interacción y después, en caso de que no exista, la confusión.
Ejemplo 9: Estudiar para los datos del ejemplo 7 la posible interacción y/o confusión.
Para estudiar interacción hay que crear la variable producto CAFXME. El modelo completo es:
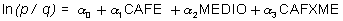
como ya se dijo antes, para este esquema de muestreo el coeficiente a0 no significa nada, a1 es el aumento del logaritmo del odds por consumir café en un ambiente rural, a2 es el aumento del logaritmo del odds por vivir en un ambiente urbano, con respecto al rural, sin consumir café y a3 modeliza la posible interacción o dicho en otros términos el "sobreaumento" por ambas cosas (consumir café en un medio urbano). El primer contraste a realizar es sobre la interacción, es decir, H0: a3=0.
La salida del SPSS para este modelo es:


Con la prueba del logaritmo del cociente de verosimilitudes, el modelo completo es significativo (p=0,000). Con la prueba de Wald para el término de interacción, no se puede rechazar (p=0,296) la hipótesis nula de no existencia de interacción y, por tanto, habría que volver a ajustar a un modelo que tuviera solamente las variable CAFE y MEDIO (el del ejemplo 7). Sin embargo, y a efectos didácticos, se va a estudiar el efecto de un error de tipo II en dicho contraste. Supóngase, por lo tanto, que el coeficiente a3 es realmente distinto de 0. En este caso no puede hablarse de un odds ratio para el café, sino que habría un odds ratio para el café en el medio rural y otro distinto en el medio urbano. Según el modelo, el odds ratio estimado para el café en el medio rural es:
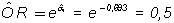
y su intervalo de confianza al 95%:
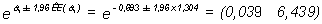
Nótese que éste es el intervalo de confianza que presenta el programa cuya salida se está analizando. No presenta, sin embargo, el que se va a calcular ahora. En general, los paquetes estadísticos calculan los intervalos de confianza asumiendo que no hay términos de interacción y, por tanto, son sólo parcialmente válidos cuando existe interacción.
Ahora, el odds ratio estimado para el café en el medio urbano es:
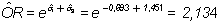
para
calcular su intervalo de confianza se necesita estimar la varianza de
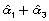
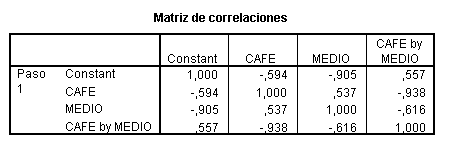
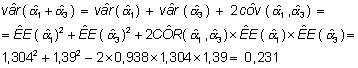
y, por tanto, su intervalo de confianza al 95%:
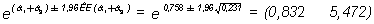
Obsérvese que en el caso de que exista interacción, los resultados son radicalmente distintos para el medio urbano (el odds ratio para el café es 2,134) que para el medio rural (el odds ratio para el café es 0,5). Si se comparan estos resultados con los del modelo sin el término de interacción:

se observa, como era de esperar, un estimador para el odds ratio del café, intermedio entre los calculados en el supuesto anterior. Conviene, por consiguiente, calcular la potencia del contraste con el que se rechazó la existencia de interacción. El contraste fue:
H0:
a3
= 0
H1: a3
¹
0
y la potencia es: 1 – b = Prob(rechazar H0|H1 verdadera). Con el nivel de significación a =0,05, se rechaza H0 si
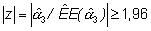
es decir si
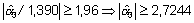
Concretando H1, por ejemplo a3=1, se trata de calcular la probabilidad de encontrar
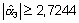
si
a3
fuera 1. Teniendo en cuenta la normalidad de 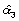
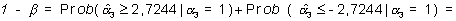
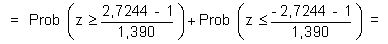
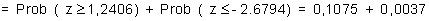
es decir, la potencia del contraste es efectivamente muy baja y habría que ser muy prudente a la hora de comunicar los resultados de este estudio.

|

|

|

|