
Modelo múltiple
Es una generalización del modelo simple:
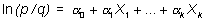
y
la interpretación de los coeficientes es también una generalización, es
decir, 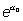 es el odds cuando todas las Xi=0 y
es el odds cuando todas las Xi=0 y 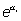 es
el odds ratio por el aumento de una unidad en la variable Xi
manteniendo constantes las otras (controlando por ellas). Nótese
que ahora la asunción de "multiplicatividad" del modelo se refiere
tanto al aumento dentro de cada variable, como a las distintas variables
y como antes, cuando no tiene sentido
físico Xi=0,
es
el odds ratio por el aumento de una unidad en la variable Xi
manteniendo constantes las otras (controlando por ellas). Nótese
que ahora la asunción de "multiplicatividad" del modelo se refiere
tanto al aumento dentro de cada variable, como a las distintas variables
y como antes, cuando no tiene sentido
físico Xi=0, 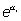 se
interpreta como el odds basal, es decir, el odds que no
depende de las variables independientes.
se
interpreta como el odds basal, es decir, el odds que no
depende de las variables independientes.
Los coeficientes se estiman y los contrastes de hipótesis se realizan del mismo modo que en el modelo simple, aunque con el modelo múltiple (igual que en regresión lineal) se pueden hacer contrastes no sólo sobre cada coeficiente, sino también sobre el modelo completo o para comparar modelos (equivalentes a los que en regresión lineal se hacen con la F y la Fpar), que en regresión logística se hacen con el llamado logaritmo del cociente de verosimilitudes (log. likelihood ratio)
Ejemplo 7: Estudiar, mediante un modelo de regresión logística, la posible asociación entre el cáncer de vejiga, el consumo de café y el ambiente de residencia. Se eligen 50 pacientes con cáncer y 50 individuos sin la enfermedad y se definen tres variables: CANCER con los valores 0 (no cáncer) y 1 (cáncer), CAFE con los valores 0 (sin consumo de café) y 1 (consumo de café) y MEDIO con los valores 0 (medio rural) y 1 (medio urbano).
Los resultados se resumen en la tabla siguiente:
| café | no café | |||
| urbano | rural | urbano | rural | |
| Cáncer | 32 | 1 | 15 | 2 |
| No cáncer | 15 | 10 | 15 | 10 |
La salida del programa de ordenador (SPSS) (¿cómo sería el archivo?):


La "Ji-cuadrado del modelo" (19,504 è p=0,000) corresponde al contraste para el modelo completo. Aunque también se puede hacer la prueba para comparar un modelo con Café y Medio con otro que sólo contenga Café:

En este caso de un bloque con una sola variable, la prueba sería equivalente a la de Wald para Medio. El que no coincidan exactamente (12,040 la de Wald y 16,864 la del logaritmo del cociente de verosimilitudes) es debido a que ambas son aproximadas. Si la discrepancia fuera muy grande indicaría que el tamaño muestral es pequeño para aplicar estas pruebas.
Es otra prueba para evaluar la bondad del ajuste de un modelo de regresión logística, aunque su uso está más discutido que la anterior. La idea es si el ajuste es bueno, un valor alto de la p predicha se asociará (con un frecuencia parecida a la p) con el resultado 1 de la variable binomial. Se trata de calcular para cada observación del conjunto de datos las probabilidades de la variable dependiente que predice el modelo, agruparlas y calcular, a partir de ellas, las frecuencias esperadas y compararlas con las observadas mediante la prueba c2.
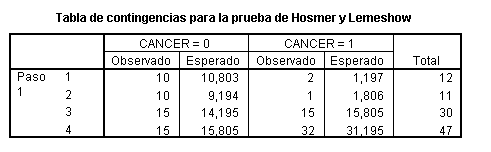
Ejemplo 8: La prueba de Hosmer-Lemeshow para el modelo del ejemplo anterior da como resultado:

Área bajo la curva ROC
La prueba de Hosmer-Lemeshow evalúa un aspecto de la validez del modelo: la calibración (grado en que la probabilidad predicha coincide con la observada).
El otro aspecto es la discriminación (grado en que el modelo distingue entre individuos en los que ocurre el evento y los que no).
Como medida de la discriminación se usa el área bajo la curva ROC construida para la probabilidad predicha por el modelo, que representa, para todos los pares posibles de individuos formados por un individuo en el que ocurrió el evento y otro en el que no, la proporción de los que el modelo predice una mayor probabilidad para el que tuvo el evento.
Para el modelo del ejemplo anterior


|

|

|

|