
Variables indicadoras ("dummy")
En los modelos de RLM la linealidad se asume. Esto, p.e. para la variable EJERC del ejemplo anterior, quiere decir que el efecto sobre el colesterol de hacer ejercicio intenso (EJERC=2) con respecto a no hacerlo (EJERC=0) es el doble que el del ejercicio moderado (EJERC=1).
¿Es razonable esta asunción? y ¿para la variable FUMA codificada como 0: no fuma, 1:fumador y 2:ex-fumador?
Una solución podría ser crear tantas variables como categorías. No sirve porque serían combinación lineal y el modelo es irresoluble.
La solución es crear tantas variables como categorías menos 1 (en los ejemplos anteriores 2) denominadas variables indicadoras con el siguiente esquema
| X1 | X2 | |
| No-fumador | 0 | 0 |
| Fumador | 1 | 0 |
| Ex-fumador | 0 | 1 |
Las variables X1 y X2 ya no son combinación lineal y, por tanto, el modelo es resoluble. El modelo quedaría
a0 es
mY cuando X1
y X2 son ambas cero, es decir, para los no-fumadores; a0 + a1 es
mY cuando X1
es 1 y X2 es 0, es decir fumadores, por lo tanto
a1
es lo que cambia mY entre
fumadores y no-fumadores y del mismo modo
a2
es lo que cambia mY entre
ex-fumadores y no-fumadores.
Con este esquema de codificación los coeficientes tienen una clara interpretación cuando, como en este caso, una de las categorías (no-fumador) se quiere usar como referencia para las demás.
A dicha categoría se le asigna el valor cero para todas las variables indicadoras. Sin embargo, para variables en las que no haya una categoría que sea natural usarla como referencia, por ejemplo genotipos, lugar de residencia, etc., es más útil otro esquema de codificación. Para discutirlo supóngase la variable lugar de residencia con cuatro lugares: A, B, C y D. Se crearán tres variables indicadoras (siempre una menos que categorías) con el siguiente esquema
|
|
X1 |
X2 |
X3 |
|
A |
-1 |
-1 |
-1 |
|
B |
1 |
0 |
0 |
|
C |
0 |
1 |
0 |
|
D |
0 |
0 |
1 |
El modelo quedará
y por lo tanto
mY = a0 - a1 - a2 - a3 = m
Y|A para los
residentes en A
mY
= a0 + a1 = mY|B para los
residentes en B
mY
= a0 + a2 = mY|C para los
residentes en C
mY
= a0 + a3 = mY|D para los
residentes en D
si se suman las 4 ecuaciones:
a0 = ( mY|A + mY|B + mY|C + mY|D)/4 por lo tanto
a0 es la media de Y en los
cuatro lugares de residencia
a1 la diferencia de los residentes en B con respecto a
la media
a2 la diferencia de los residentes en C con respecto a
la media y
a3 la diferencia de los residentes en D con respecto a
la media y, evidentemente, -
a1 - a2 - a3
la
diferencia de los residentes en A con respecto a la media. De modo que a
diferencia del esquema anterior, se usa como nivel de referencia la media en
todas las categorías en lugar de una de ellas.
Otro posible esquema de codificación que a veces se usa en la literatura es
|
X1 |
X2 |
X3 |
|
|
A |
1 |
1 |
1 |
|
B |
0 |
1 |
1 |
|
C |
0 |
0 |
1 |
|
D |
0 |
0 |
0 |
y queda para el lector, a modo de ejercicio, la interpretación de los coeficientes de regresión en este caso.
Conviene destacar que estas variables indicadoras no tienen ningún sentido por sí solas y por, lo tanto, deben figurar en los modelos y se debe contrastar su inclusión siempre en bloque, usando la F del modelo completo si sólo están dichas variables en el modelo, o la F parcial correspondiente a las mismas si hay más variables.
Ejercicio propuesto : Para los datos del Ejemplo 5, crear "dummys" para el ejercicio (¿con qué esquema?) y contrastar (con la F parcial) si estas variables mejoran el modelo que sólo contiene edad y grasas. Interpretar los coeficientes.
Ejemplo 7: Considérense los siguientes datos, procedentes de una muestra hipotética, sobre presión arterial en cm de Hg y "status" de fumador, codificado como 0: no-fumador, 1: fumador y 2: ex-fumador. Discutir el modelo de regresión entre presión arterial y "status" de fumador y estimar por intervalos la presión arterial media según el "status" de fumador, a partir de los resultados del modelo más adecuado.
| Paciente | Presión arte. | Fumador |
| 1 | 15,0 | 0 |
| 2 | 19,0 | 2 |
| 3 | 16,3 | 1 |
| 4 | 22,0 | 1 |
| 5 | 18,0 | 2 |
| 6 | 19,8 | 0 |
| 7 | 23,2 | 1 |
| 8 | 14,4 | 0 |
| 9 | 20,3 | 2 |
| 10 | 22,0 | 1 |
| 11 | 20,5 | 2 |
| 12 | 19,0 | 2 |
| 13 | 12,7 | 0 |
| 14 | 14,0 | 0 |
| 15 | 11,8 | 0 |
| 16 | 11,2 | 2 |
| 17 | 14,0 | 0 |
| 18 | 19,5 | 1 |
| 19 | 22,3 | 1 |
| 20 | 15,0 | 0 |
| 21 | 12,6 | 2 |
| 22 | 16,4 | 0 |
| 23 | 13,5 | 2 |
| 24 | 13,7 | 1 |
Los resultados de un modelo entre presión arterial y "status" de fumador tal y como está codificado en la tabla son:
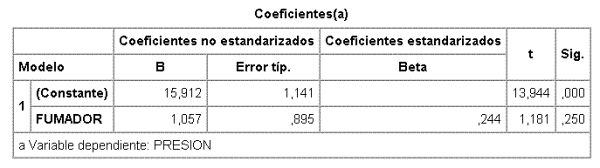
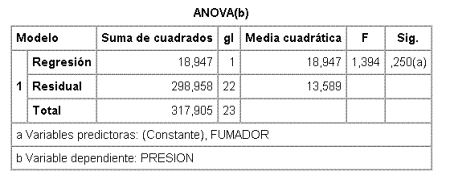
En este caso de una única variable independiente, el contraste sobre el modelo global con la F es equivalente al realizado con la t sobre el coeficiente a1 y con ninguno se puede rechazar la hipótesis nula (p=0,250) de no dependencia. Es decir, analizado de este modo no hay dependencia entre ambas variables.
Si se crean dos variables indicadoras (FUMA y EX_FUMA) con el primer esquema discutido antes la tabla de datos queda
| PACIEN | PRE_AR | FUMADOR | FUMA | EX_FUMA |
| 1 | 15.0 | 0 | 0 | 0 |
| 2 | 19.0 | 2 | 0 | 1 |
| 3 | 16.3 | 1 | 1 | 0 |
| 4 | 22.0 | 1 | 1 | 0 |
| 5 | 18.0 | 2 | 0 | 1 |
| 6 | 19.8 | 0 | 0 | 0 |
| 7 | 23.2 | 1 | 1 | 0 |
| 8 | 14.4 | 0 | 0 | 0 |
| 9 | 20.3 | 2 | 0 | 1 |
| 10 | 22.0 | 1 | 1 | 0 |
| 11 | 20.5 | 2 | 0 | 1 |
| 12 | 19.0 | 2 | 0 | 1 |
| 13 | 12.7 | 0 | 0 | 0 |
| 14 | 14.0 | 0 | 0 | 0 |
| 15 | 11.8 | 0 | 0 | 0 |
| 16 | 11.2 | 2 | 0 | 1 |
| 17 | 14.0 | 0 | 0 | 0 |
| 18 | 19.5 | 1 | 1 | 0 |
| 19 | 22.3 | 1 | 1 | 0 |
| 20 | 15.0 | 0 | 0 | 0 |
| 21 | 12.6 | 2 | 0 | 1 |
| 22 | 16.4 | 0 | 0 | 0 |
| 23 | 13.5 | 2 | 0 | 1 |
| 24 | 13.7 | 1 | 1 | 0 |
y el modelo entre PRE_AR y FUMA y EX_FUMA
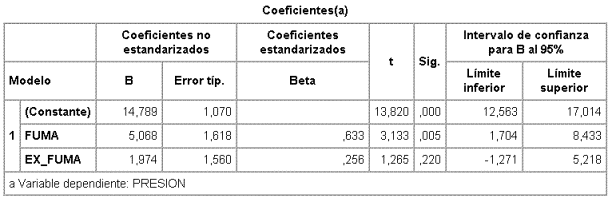
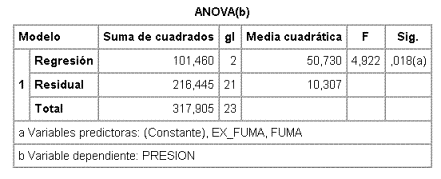
Para contrastar si la presión arterial depende del "status" de fumador, deberá usarse el contraste basado en la F (p=0,018) y por lo tanto al nivel de significación habitual a =0,05 se rechaza la hipótesis nula de no dependencia. A pesar de que el coeficiente para EX_FUMA no es significativamente distinto de 0 (p=0,220), se mantiene en el modelo porque FUMA no tiene sentido por sí sola.
Obsérvese que usando las variables indicadoras se ha encontrado una dependencia que antes no se había puesto de manifiesto, debido a la falta de linealidad para los códigos usados.
La estimación puntual de la presión arterial media de los no-fumadores (a0 en el modelo) es 14,789 con un error estándar estimado de 1,07 y, como t0,025(21) = 2,08, su intervalo de confianza al 95% es 14,789 ± 2,08x1,07 = (12,563 17,014).
La estimación del aumento medio de la presión arterial en los fumadores (a1) es 5,068 que es significativamente distinto de cero (p=0,005) y la estimación del aumento medio de la presión arterial en los ex-fumadores (a2) es 1,974 pero no es significativamente distinto de cero (p=0,220).
Para realizar la estimación por intervalos de la presión media en fumadores (a0+ a1) y ex-fumadores (a0 + a2) se necesita estimar sus respectivas varianzas
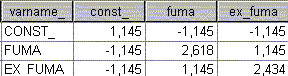
var(a0 + a1) = var( a0) + var( a1) + 2cov( a0 , a1) = 1,145 + 2,618 - 2 x 1,145 = 1,473
EE(a0 + a1) = 1,214
var(a0 + a2) = var( a0) + var( a2) + 2cov( a0 , a2) = 1,145 + 2,434 - 2 x 1,145 = 1,289
EE(a0 + a2) = 1,135
Por lo tanto los intervalos de confianza al 95% para la presión arterial media de fumadores y ex-fumadores son
fumadores: (14,789+5,068)
±
2,08x1,214 = (17,332 22,382)
ex-fumad : (14,789+1,974) ±
2,08x1,135
= (14,402 19,124)
recordemos que para no-fumadores se había obtenido
no-fumad : 14,789 ± 2,08x1,07 = (12,563 17,015)
y que la diferencia entre no-fumadores y ex-fumadores no es significativa, mientras que la diferencia entre no-fumadores y fumadores sí lo es.

|

|

|

|