
Casos particulares: Anova de dos factores sin repetición
En ciertos estudios en que los datos son difíciles de obtener o presentan muy poca variabilidad dentro de cada subgrupo es posible plantearse un anova sin repetición, es decir, en el que en cada muestra sólo hay una observación (n=1). Hay que tener en cuenta que, como era de esperar con este diseño, no se puede calcular SSE. El término de interacción recibe el nombre de residuo y que, como no se puede calcular MSE, no se puede contrastar la hipótesis de existencia de interacción.
Esto último implica también que:
a) en un modelo I, para poder contrastar las hipótesis de existencia de efectos de los factores no debe haber interacción (si hubiera interacción no tenemos término adecuado para realizar el contraste).
b) en un modelo mixto existe el mismo problema para el factor fijo.
Bloques completos aleatoriosOtro diseño muy frecuente de anova es el denominado de bloques completos aleatorios diseñado inicialmente para experimentos agrícolas pero actualmente muy extendido en otros campos. Puede considerarse como un caso particular de un anova de dos factores sin repetición o como una extensión al caso de k muestras de la comparación de medias de dos muestras emparejadas. Se trata de comparar k muestras emparejadas con respecto a otra variable cuyos efectos se quieren eliminar.
Por ejemplo, en un ensayo clínico para comparar los efectos de dos analgésicos y un placebo en el que el efecto se mide por el tiempo que tarda en desaparecer una cefalea. Si se hicieran tres grupos de enfermos y a cada uno de ellos se le suministrara un tratamiento distinto, habría una gran variación individual en las respuestas, debido a que no todas las cefaleas son de la misma intensidad y no todos los individuos tienen la misma percepción del dolor, que dificultaría el hallazgo de diferencias entre los tratamientos. Esta dificultad desaparece si se aplican los tres tratamientos a los mismos individuos en diferentes episodios de cefalea. Se ha emparejado a cada individuo consigo mismo, con lo que se elimina la variación individual.
En este diseño a los datos de cada individuo se les denomina bloque y los datos se representan en una tabla de doble entrada análoga a la del anova de clasificación única en la que las a columnas son los tratamientos y las b filas los bloques, el elemento Yij de la tabla corresponde al tratamiento i y al bloque j. Las hipótesis que se pueden plantear son:
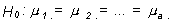 (igualdad de medias de tratamientos)
(igualdad de medias de tratamientos)
y también, aunque generalmente tiene menos interés:
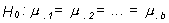 (igualdad de medias de bloques)
(igualdad de medias de bloques)
A pesar del parecido con la clasificación única, el diseño es diferente: allí las columnas eran muestras independientes y aquí no. Realmente es un diseño de dos factores, uno de efectos fijos: los tratamientos, y el otro de efectos aleatorios: los bloques, y sin repetición: para cada bloque y tratamiento sólo hay una muestra.
El modelo aquí es:
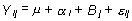 donde ai
es el efecto del tratamiento i y Bj el del bloque j. No hay término de interacción ya que,
al no poder contrastar su existencia no tiene interés. Al ser un modelo mixto
exige la asunción de no existencia de interacción y los contrastes se hacen
usando el término MSE como divisor.
donde ai
es el efecto del tratamiento i y Bj el del bloque j. No hay término de interacción ya que,
al no poder contrastar su existencia no tiene interés. Al ser un modelo mixto
exige la asunción de no existencia de interacción y los contrastes se hacen
usando el término MSE como divisor.

|

|

|

|